Ngoại suy tri thức (Knowledge Extrapolation) cho đồ thị tri thức (Knowledge Graphs)
Động lực nghiên cứu
Trong nhiều ứng dụng thực tế như các cơ sở dữ liệu đồ thị (graph database systems), hệ thống gợi ý (recommendation systems), hay hệ thống trả lời câu hỏi (question answering sytems), đồ thị tri thức (knowledge graphs - KG) đóng vai trò là nguồn tri thức giá trị. Có nhiều hướng tiếp cận cho các phương pháp khai thác loại cơ sở tri thức này, và trong đó hướng tiếp cận nhúng đồ thị tri thức (knowledge graph embedding - KGE) là một trong những hướng tiếp cận khả thi và hiệu quả cho nhiều tác vụ downstream như dự đoán liên kết (link prediction/ missing fact completion), hiệu chỉnh thực thể (entity alignment). Tuy nhiên, các phương pháp KGE vẫn phải đối mặt với nhiều vấn đề và thách thức, trong đó vấn đề xử lý các thực thể hay quan hệ chưa biết (unseen objects - entities/ relations) trong quá trình đánh giá/ triển khai mô hình là một trong những khó khăn đó.
Lấy động lực từ vấn đề này, một hướng nghiên cứu mới ra đời dựa trên hàng loạt các công trình gần đây, ngoại suy tri thức (Knowledge Extrapolation - KE) được hình thành. Trong notes này, chúng tôi dựa trên bài báo Generalizing to Unseen Elements: A Survey on Knowledge Extrapolation for Knowledge Graphs của Mingyang Chen để tổng hợp và trình bày bổ sung các phương pháp gần đây cho hướng nghiên cứu KE.
Nếu bạn đọc có quan tâm đến hướng nghiên cứu này, vui lòng đọc paper để có thêm thông tin chi tiết:
Chen, M., Zhang, W., Geng, Y., Xu, Z., Pan, J. Z., & Chen, H. (2023). Generalizing to Unseen Elements: A Survey on Knowledge Extrapolation for Knowledge Graphs. arXiv preprint arXiv:2302.01859.
Nhúng đồ thị tri thức (knowledge graph embedding)
Ta định nghĩa một cách hình thức đồ thị tri thức là $\mathcal{G} = \{\mathcal{E}, \mathcal{R}, \mathcal{T}\}$, trong đó:
- $\mathcal{E}$ là tập hợp các thực thể (entities).
- $\mathcal{R}$ là tập hợp các quan hệ (relations).
- $\mathcal{T}$ là tập hợp các bộ ba dữ liệu (fact triplets). Một bộ ba dữ liệu biểu diễn một mối liên hệ giữa hai thực thể thông qua một quan hệ, và có thể được biểu diễn như một tập hợp $\{h, r, t\} \subseteq \mathcal{E} \times \mathcal{R} \times \mathcal{E}$
Do cơ sở tri thức này có cấu trúc đồ thị, nên ta hoàn toàn có thể biểu diễn nó thông qua ma trận kề. Tuy nhiên, cách này rất tốn kém, và điều đó thật là không hiệu quả. Thay vì sử dụng phương pháp nhúng “ngây thơ” như vậy, người ta sử dụng phương pháp đơn giản mà hiệu quả hơn “nhúng tra nông”, “shallow lookup embedding" 1. Trong shallow embedding, bộ mã hóa được định nghĩa bằng một “bảng tra” sao cho tính tương đồng trong không gian này có thể xấp xỉ tính tương đồng trong không gian trước đó. Mỗi một cột của ma trận này thể hiệu bảng nhúng của nút, còn tổng số dòng của ma trận thể hiện số chiều nhúng/ kích thước nhúng. Hơn nữa, ta cũng cần phải phân biệt giữa “shallow embedding” và “deep embedding”. . Nói chung, mục tiêu chính của phương pháp nhúng đồ thị tri thức là biểu diễn các phần trong các tập hợp thực tể $\mathcal{E}$ và quan hệ $\mathcal{R}$ vào không gian vector liên tục thấp chiều trong khi vẫn bảo toàn cấu trúc nội tại của dữ liệu đồ thị.
Để đánh giá một phương pháp nhúng đồ thị tri thức có tốt hay không, người ta thường khảo sát tác tục dự đoán liên kết(có thể hiểu là dự đoán các bộ dữ kiện bị thiếu, điều này chưa đúng đắn về mặt bản chất nhưng ta vẫn có thể chấp nhận được) cho việc đánh giá mức độ hiệu quả của phương pháp KGE được đề xuất.
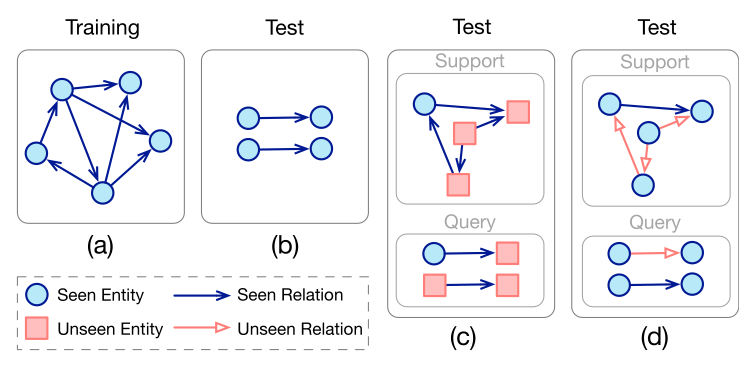
(a) Tập huấn luyện (training), và (b) Tập kiểm tra (test) cho KGE truyền thống. Ví dụ về tập kiểm tra cho thiết lập bài toán ngoại suy thực thể (c) và thiết lập bài toán ngoại suy quan hệ (d). Trong đó có thể có bất kỳ thông tin bổ trợ nào về những thực thể chưa biết trong tập hỗ trợ (support set), và sử những bộ ba dữ kiện liên quan như những ví dụ.
Các phương pháp được đề xuất cho thiết lập ngoại suy tri thức có mục tiêu thực hiện dự đoán liên kết trên những phần tử chưa biết (unseen elements). Một cách thống nhất, trong quá trình ngoại suy tri thúc, có hai tập được sử dụng cho đánh giá:
- Một tập cung cấp thông tin hỗ trợ về những phần tử chưa biết;
- Tập còn lại đánh giá khả năng dự đoán liên kết của mô hình.
Về mặt phân loại, ta có thể chia các phương pháp tiếp cận hiện tại theo hai hướng: ngoại suy thực thể (Entity Extrapolation), và ngoại suy quan hệ (Relation Extrapolation). Hình bên dưới thể hiện tổng quan hệ thống phân loại các phương pháp tiếp cận.
Các phương pháp ngoại suy thực thể (Entity extrapolation methods)
Mã hóa thực thể (Entity encoding)
Một trong những cách để xử lý những thực thể chưa biết đó là học cách mã hóa những thực thể thay vì học các bảng nhúng “cố định”. Những bộ mã hóa học được này (learned encoders) có thể thực thi trên tập hợp hỗ trợ của các thực thể để tạo ra các bảng nhúng hợp lý (reasonable embeddings) cho chúng. Hiện nay, có nhiều cách để thiết kế các mô hình mã hóa này. Tùy thuộc vào tính chất của tập hỗ trợ mà ta có thể chọn lựa các phương pháp tiếp cận phù hợp.
- Encode from structural information (khi tập support chỉ chứa những thông tin về bộ ba chưa biết):
- (MEAN) Bi, Z., Zhang, T., Zhou, P., & Li, Y. (2020). Knowledge transfer for out-of-knowledge-base entities: Improving graph-neural-network-based embedding using convolutional layers. IEEE Access, 8, 159039-159049.
- (LAN) Wang, P., Han, J., Li, C., & Pan, R. (2019, July). Logic attention based neighborhood aggregation for inductive knowledge graph embedding. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 7152-7159).
- Bhowmik, R., & de Melo, G. (2020). Explainable link prediction for emerging entities in knowledge graphs. In The Semantic Web–ISWC 2020: 19th International Semantic Web Conference, Athens, Greece, November 2–6, 2020, Proceedings, Part I 19 (pp. 39-55). Springer International Publishing.
- Albooyeh, M., Goel, R., & Kazemi, S. M. (2020, November). Out-of-sample representation learning for knowledge graphs. In Findings of the Association for Computational Linguistics: EMNLP 2020 (pp. 2657-2666).
- (CFAG) Wang, C., Zhou, X., Pan, S., Dong, L., Song, Z., & Sha, Y. (2022, June). Exploring Relational Semantics for Inductive Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 4, pp. 4184-4192).
- (ARGCN) Cui, Y., Wang, Y., Sun, Z., Liu, W., Jiang, Y., Han, K., & Hu, W. (2022, October). Inductive knowledge graph reasoning for multi-batch emerging entities. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (pp. 335-344).
- (QBLP) Ali, M., Berrendorf, M., Galkin, M., Thost, V., Ma, T., Tresp, V., & Lehmann, J. (2021). Improving inductive link prediction using hyper-relational facts. In The Semantic Web–ISWC 2021: 20th International Semantic Web Conference, ISWC 2021, Virtual Event, October 24–28, 2021, Proceedings 20 (pp. 74-92). Springer International Publishing.
- (GEN) Baek, J., Lee, D. B., & Hwang, S. J. (2020). Learning to extrapolate knowledge: Transductive few-shot out-of-graph link prediction. Advances in Neural Information Processing Systems, 33, 546-560.
- (HRFN) Zhang, Y., Wang, W., Chen, W., Xu, J., Liu, A., & Zhao, L. (2021, October). Meta-learning based hyper-relation feature modeling for out-of-knowledge-base embedding. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (pp. 2637-2646).
- (INDIGO) Liu, S., Grau, B., Horrocks, I., & Kostylev, E. (2021). Indigo: Gnn-based inductive knowledge graph completion using pair-wise encoding. Advances in Neural Information Processing Systems, 34, 2034-2045.
- (MorsE) Chen, M., Zhang, W., Zhu, Y., Zhou, H., Yuan, Z., Xu, C., & Chen, H. (2022, July). Meta-knowledge transfer for inductive knowledge graph embedding. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 927-937).
- (NodePiece) Galkin, M., Denis, E., Wu, J., & Hamilton, W. L. (2021). Nodepiece: Compositional and parameter-efficient representations of large knowledge graphs. arXiv preprint arXiv:2106.12144.
- Encode from other information (khi tập support có chứa những thông tin khác):
- (DKRL) Xie, R., Liu, Z., Jia, J., Luan, H., & Sun, M. (2016, March). Representation learning of knowledge graphs with entity descriptions. In Proceedings of the AAAI conference on artificial intelligence (Vol. 30, No. 1).
- (ConMask) Shi, B., & Weninger, T. (2018, April). Open-world knowledge graph completion. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1).
- (OWE) Shah, H., Villmow, J., Ulges, A., Schwanecke, U., & Shafait, F. (2019, July). An open-world extension to knowledge graph completion models. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01, pp. 3044-3051).
- (KEPLER) Wang, X., Gao, T., Zhu, Z., Zhang, Z., Liu, Z., Li, J., & Tang, J. (2021). KEPLER: A unified model for knowledge embedding and pre-trained language representation. Transactions of the Association for Computational Linguistics, 9, 176-194.
- (StAR) Wang, B., Shen, T., Long, G., Zhou, T., Wang, Y., & Chang, Y. (2021, April). Structure-augmented text representation learning for efficient knowledge graph completion. In Proceedings of the Web Conference 2021 (pp. 1737-1748).
- (BLP) Daza, D., Cochez, M., & Groth, P. (2021, April). Inductive entity representations from text via link prediction. In Proceedings of the Web Conference 2021 (pp. 798-808).
- (SimKGC) Wang, L., Zhao, W., Wei, Z., & Liu, J. (2022). SimKGC: Simple contrastive knowledge graph completion with pre-trained language models. arXiv preprint arXiv:2203.02167.
- (StATIK) Markowitz, E., Balasubramanian, K., Mirtaheri, M., Annavaram, M., Galstyan, A., & Ver Steeg, G. (2022, July). StATIK: Structure and text for inductive knowledge graph completion. In Findings of the Association for Computational Linguistics: NAACL 2022 (pp. 604-615).
Dự đoán đồ thị con (Subgraph predicting)
- (GraIL) Teru, K., Denis, E., & Hamilton, W. (2020, November). Inductive relation prediction by subgraph reasoning. In International Conference on Machine Learning (pp. 9448-9457). PMLR.
- (CoMPILE) Mai, S., Zheng, S., Yang, Y., & Hu, H. (2021, May). Communicative message passing for inductive relation reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 5, pp. 4294-4302).
- (TACT) Chen, J., He, H., Wu, F., & Wang, J. (2021, May). Topology-aware correlations between relations for inductive link prediction in knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 7, pp. 6271-6278).
- (ConGLR) Lin, Q., Liu, J., Xu, F., Pan, Y., Zhu, Y., Zhang, L., & Zhao, T. (2022, July). Incorporating context graph with logical reasoning for inductive relation prediction. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 893-903).
- (SNRI) Xu, X., Zhang, P., He, Y., Chao, C., & Yan, C. (2022). Subgraph neighboring relations infomax for inductive link prediction on knowledge graphs. arXiv preprint arXiv:2208.00850.
- (BertRL) Zha, H., Chen, Z., & Yan, X. (2022, June). Inductive relation prediction by BERT. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 5, pp. 5923-5931).
- (RMPI) Geng, Y., Chen, J., Pan, J. Z., Chen, M., Jiang, S., Zhang, W., & Chen, H. (2023, April). Relational message passing for fully inductive knowledge graph completion. In 2023 IEEE 39th International Conference on Data Engineering (ICDE) (pp. 1221-1233). IEEE.
- (PathCon) Wang, H., Ren, H., & Leskovec, J. (2021, August). Relational message passing for knowledge graph completion. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (pp. 1697-1707).
- (NBFNet) Zhu, Z., Zhang, Z., Xhonneux, L. P., & Tang, J. (2021). Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems, 34, 29476-29490.
- (RED-GNN) Zhang, Y., & Yao, Q. (2022, April). Knowledge graph reasoning with relational digraph. In Proceedings of the ACM web conference 2022 (pp. 912-924).
Dựa trên khai thác luật (Rule mining)
- (AMIE) Galárraga, L. A., Teflioudi, C., Hose, K., & Suchanek, F. (2013, May). AMIE: association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd international conference on World Wide Web (pp. 413-422).
- (RuleN) Meilicke, C., Fink, M., Wang, Y., Ruffinelli, D., Gemulla, R., & Stuckenschmidt, H. (2018). Fine-grained evaluation of rule-and embedding-based systems for knowledge graph completion. In The Semantic Web–ISWC 2018: 17th International Semantic Web Conference, Monterey, CA, USA, October 8–12, 2018, Proceedings, Part I 17 (pp. 3-20). Springer International Publishing.
- (AnyBURL) Meilicke, C., Chekol, M. W., Ruffinelli, D., & Stuckenschmidt, H. (2019, August). Anytime Bottom-Up Rule Learning for Knowledge Graph Completion. In IJCAI (pp. 3137-3143).
- (NeuralLP) Yang, F., Yang, Z., & Cohen, W. W. (2017). Differentiable learning of logical rules for knowledge base reasoning. Advances in neural information processing systems, 30.
- (DRUM) Sadeghian, A., Armandpour, M., Ding, P., & Wang, D. Z. (2019). Drum: End-to-end differentiable rule mining on knowledge graphs. Advances in Neural Information Processing Systems, 32.
- (CBGNN) Yan, Z., Ma, T., Gao, L., Tang, Z., & Chen, C. (2022, June). Cycle representation learning for inductive relation prediction. In International Conference on Machine Learning (pp. 24895-24910). PMLR
Các phương pháp ngoại suy quan hệ (Relation extrapolation methods)
Mã hóa quan hệ (Relation encoding)
- Encode from structural information (khi tập support chỉ chứa những thông tin về bộ ba chưa biết):
- (MetaR) Chen, M., Zhang, W., Zhang, W., Chen, Q., & Chen, H. (2019). Meta relational learning for few-shot link prediction in knowledge graphs. arXiv preprint arXiv:1909.01515.
- (GANA) Niu, G., Li, Y., Tang, C., Geng, R., Dai, J., Liu, Q., … & Si, L. (2021, July). Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion. In Proceedings of the 44th International ACM SIGIR conference on research and development in information retrieval (pp. 213-222).
- Encode from other information (khi tập support có chứa những thông tin khác):
- (ZSGAN) Qin, P., Wang, X., Chen, W., Zhang, C., Xu, W., & Wang, W. Y. (2020, April). Generative adversarial zero-shot relational learning for knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 05, pp. 8673-8680).
- (OntoZSL) Geng, Y., Chen, J., Chen, Z., Pan, J. Z., Ye, Z., Yuan, Z., … & Chen, H. (2021, April). Ontozsl: Ontology-enhanced zero-shot learning. In Proceedings of the Web Conference 2021 (pp. 3325-3336).
- (DMoG) Song, R., He, S., Zheng, S., Gao, S., Liu, K., Yu, Z., & Zhao, J. (2022, October). Decoupling Mixture-of-Graphs: Unseen Relational Learning for Knowledge Graph Completion by Fusing Ontology and Textual Experts. In Proceedings of the 29th International Conference on Computational Linguistics (pp. 2237-2246).
- (HAPZSL) Li, X., Ma, J., Yu, J., Xu, T., Zhao, M., Liu, H., … & Yu, R. (2022). HAPZSL: A hybrid attention prototype network for knowledge graph zero-shot relational learning. Neurocomputing, 508, 324-336.
- (DOZSL) Geng, Y., Chen, J., Zhang, W., Xu, Y., Chen, Z., Z. Pan, J., … & Chen, H. (2022, August). Disentangled ontology embedding for zero-shot learning. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining (pp. 443-453).
Khớp cặp thực thể (Entity pair matching)
Các công trình tiêu biểu
- (GMatching) Xiong, W., Yu, M., Chang, S., Guo, X., & Wang, W. Y. (2018). One-shot relational learning for knowledge graphs. arXiv preprint arXiv:1808.09040.
- (FSRL) Zhang, C., Yao, H., Huang, C., Jiang, M., Li, Z., & Chawla, N. V. (2020, April). Few-shot knowledge graph completion. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, No. 03, pp. 3041-3048).
- (FAAN) Sheng, J., Guo, S., Chen, Z., Yue, J., Wang, L., Liu, T., & Xu, H. (2020). Adaptive attentional network for few-shot knowledge graph completion. arXiv preprint arXiv:2010.09638.
- (MetaP) Jiang, Z., Gao, J., & Lv, X. (2021, July). Metap: Meta pattern learning for one-shot knowledge graph completion. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2232-2236).
- (P-INT) Xu, J., Zhang, J., Ke, X., Dong, Y., Chen, H., Li, C., & Liu, Y. (2021, November). P-INT: A path-based interaction model for few-shot knowledge graph completion. In Findings of the Association for Computational Linguistics: EMNLP 2021 (pp. 385-394).
- (GraphANGEL) Jin, J., Wang, Y., Du, K., Zhang, W., Zhang, Z., Wipf, D., … & Gan, Q. (2021, October). Inductive Relation Prediction Using Analogy Subgraph Embeddings. In International Conference on Learning Representations.
- (CSR) Huang, Q., Ren, H., & Leskovec, J. (2022). Few-shot relational reasoning via connection subgraph pretraining. Advances in Neural Information Processing Systems, 35, 6397-6409.
Dữ liệu
Các bộ dữ liệu:
- WN11-{Head/Tail/Both}-{1,000/3,000/5,000}
- Được đề xuất bởi
- {WN18RR/FB15k-237/NELL995}-{v1/2/3/4}
- NELL-One/Wiki-One
- NELL-ZS/Wiki-ZS
Bàn luận
Bàn luận 1: Những gia định về ngoại suy thực thể
Thường có hai giả định khác nhau về ngoại suy thực thể (entity extroplation).
- Giả định thứ nhất: các thực thể chưa biết trong tập support được liên kết với những thực thể đã biết. Giả định này được gọi là bán ngoại suy thực thể (semi-entity extrapolation).
- Giả định thứ hai: các thực thể chưa biết tạo thành một đồ thị tri thức hoàn toàn mới trong các tập support và không liên kết bởi các thực thể đã biết. Giả định này được gọi là ngoại suy thực thể hoàn toàn (fully-entity extrapolation).
Như vậy, ta hoàn toàn có thể thấy các mô hình được thiết kế để giải quyết cho vấn đề ngoại suy hoàn toàn thì có thể áp dụng để giải quyết cho trường hợp bán ngoại suy, nhưng chiều ngược lại thì không được.
Hầu hết các mô hình bán ngoại suy thực thể nằm trong nhóm các mô hình dựa trên mã hóa thực thể và mã hóa thực thể chưa biết từ thông tin cấu trúc bởi vì chúng thường thiết kế các module cho việc chuyển giao tri thức từ các thực thể đã biết. Một số mô hình thiết kế bộ mã hóa độc lập với thực thể khiến chúng có thể giải quyết vấn đề ngoại suy hoàn toàn.
Các phương pháp mã hóa các thực thể chưa biết từ các nguồn thông tin khác như thông tin văn bản mô tả cũng có thể giải quyết được bài toán ngoại suy hoàn toàn. Các phương pháp dựa trên dự đoán đồ thị con và học dựa trên luật có khả năng xử lý bài toán ngoại suy hoàn toàn bởi vì các đồ thị con và luật thì độc lập với thực thể.
Bàn luận 2: Khai thác thông tin trong tập support
Nhiều thể loại thông tin có thể được khai thác để xây dựng các tập support cho các thành phần chưa biết, bao gồm các bộ ba dữ kiện, mô tả ngữ cảnh, và bản thể học (ontologies). Chúng ta sẽ lần lượt xem xét từng thể loại một.
Đầu tiên, các bộ ba dữ kiện, mà cung cấp thông tin cấu trúc, một kiểu trực quan của thông tin hỗ trợ cho các thành phần chưa biết bởi chúng thường xuất hiện với những thành phần khác trong dạng thức của một bộ ba dữ kiện thay vì đứng một mình. Tri thức từ những thành phần đă biết được cung cấp bởi các bộ ba mà có thể sử dụng bởi các thành phần chưa biết.
Bên cạnh đó, thông tin mô tả ngữ cảnh cũng phổ biến cho KG bởi vì nhiều KG được xây dựng từ dữ liệu văn bản. Mô tả ngữ cảnh có thể cung cấp một cách tự nhiên khả năng ngoại suy đến cho những thành phần chưa biết, và thường được sử dụng trong các bộ mã hóa văn bản để biến đổi văn bản thành các embeddings.
Cuối cùng, bản thế học (ontologies) thường được sử dụng như tri thức tiên nghiệm (prior knowledge) về mối tương quan giữa các thành phần đã biết và chưa biết, và được sử dụng giải quyết các quan hệ chưa biết trong nhiều trong trình hiện nay. Một ontology thường được thể hiện như một đồ thị bao gồm các quan hệ phân cấp và ràng buộc trên các miền và khoảng quan hệ. Embedding của các quan hệ chưa biết có thể được phát sinh bằng cách sử dụng một phương pháp dựa trên ontology mà sử dụng nhiều kỹ thuật bao gồm GAN hay disentangled representation learning.
Các định hướng tương lai
Định hướng 1: Khai thác vào các ứng dụng
Hầu hết các phương pháp ngoại suy tri thức hiện nay được đánh giá dựa trên bài toán dự đoán liên kết trên các tập kiểm tra. Mặc dù tác vụ dự đoán liên kết có thể cho thấy tính hiệu quả của mô hình và giúp đồ thị tri thức hoàn thiện, nó cũng có giá trị để khám phát cách để phát sinh những thành phần chưa biết của KG trong nhiều ứng dụng như: answering logical queries expressed in a subset of first-order logic; entity alignment task under the growing KG; question answering; …
Định hướng 2: Thông tin hỗ trợ đa thể thức
Đồ thị tri thức đa thể thức (Multi-modal knowledge graphs) là một trong những chủ đề nghiên cứu được đề cập nhiều trong thời gian gần đây. Trong khi nhiều phương pháp ngoại suy tri thức tập trung vào việc sử dụng ngôn ngữ tự nhiên như trong tin hỗ trợ cho các thành phần chưa biết, thì có tương đối ít các công trình giải quyết vấn đề tiềm năng của việc sử dụng thông tin thị giác.
Định hướng 3: Ngoại suy thực thể và quan hệ
Các nghiên cứu hiện tại trên vấn đề ngoại suy tập trung chủ yếu vào việc giải quyết ngoại suy thực thể và quan suy quan hệ một cách hoàn toàn độc lập, nhưng trong nhiều ứng dụng thực tế, các thực thể và quan hệ chưa biết có thể xuất hiện một cách đồng thời. Một lời giải khả thi ở đây là các phương pháp tích hợp một cách hiệu quả cả ngoại suy thực thể và quan hệ.
Định hướng 4: Thiết lập động và lifelong
Trong nhiều ứng dụng thực tế, một số KG bao gồm các ràng buộc thời gian mà thỏa mãn một số xem xét về thông tin thời gian khi mà đánh giá điểm cho một bộ ba nào đó. Đồ thị tri thức động cũng đối mặt với thách thức về việc xuất hiện của các thành phần bởi vì bản chất động của nó. Để giải quyết vấn đề này, nhiều công trình định nghĩa một bài toán về ngoại suy thực thể trong đồ thị động và sử dụng các kỹ thuật để thu được các embedding cho các thực thể chưa biết.
Tài liệu tham khảo
[1] Chen, M., Zhang, W., Geng, Y., Xu, Z., Pan, J. Z., & Chen, H. (2023). Generalizing to Unseen Elements: A Survey on Knowledge Extrapolation for Knowledge Graphs. arXiv preprint arXiv:2302.01859.